
MAR: MEDICAL ASYMMETRIC RETRIEVER FOR EFFICIENT CHINESE MEDICAL DENSE RETRIEVAL 阅读笔记
金培晟 Jarfield
0 摘要
本文提出中文医学文本嵌入基准 MedTEB,覆盖三类贴近真实场景的任务:检索、重排序与医学同义句相似度(STS)。在构建过程中,我们采用基于多模型的 LLM 标注流程以提升数据质量。对强通用嵌入模型在 MedTEB 上的评测显示,该基准具有面向领域且更具挑战性的检索评测价值。基于此,我们提出医学非对称检索器(MAR):将查询与文档编码解耦,在线用轻量查询编码器实现低延迟,离线用更强大的(LLM-based)文档编码器保证检索质量。为优化这一非对称架构,我们引入两阶段训练框架:(1)查询编码器对齐;(2) 联合微调。实验表明,MAR 在 MedTEB 上取得SOTA 性能,同时其推理速度与小型 BERT 类嵌入模型相当,兼顾准确率与效率,适用于真实的中文医学检索场景。代码、数据与模型将公开以促进后续研究。
1 引言
背景与动机
向量表征(embedding)是现代 NLP 的基础,广泛用于检索、重排、分类,并是 RAG 的关键组件。
医疗等专门领域中,LLM 往往缺乏深度专家知识;因此需要准确且低延迟地访问医学知识,以提升临床决策支持并减少 RAG 幻觉:领域化、低延迟的医学嵌入是刚需。
现状与差距
通用嵌入模型进展很快,但中文医学文本嵌入关注不足。
现有基准如 C-MTEB 仅含两套中文医学检索数据,且存在标注噪声与假负例。
当前强力嵌入多为LLM-based:性能强但延迟与算力成本高,限制实时医疗问答等敏感场景。
基准贡献(MedTEB)
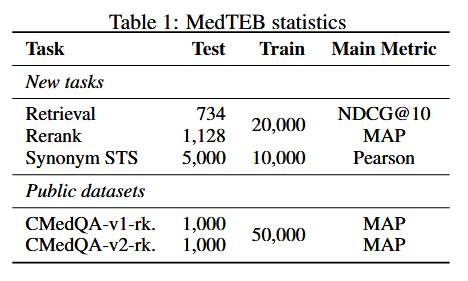
MedTEB:包含检索、重排序、医学同义句 STS三类全新整理任务,并纳入两套公开数据。
使用LLM 驱动的标注流程提升标签质量。
评测显示:即便强大的通用嵌入模型在 MedTEB 上表现也不佳,证明其难度与领域针对性。
方法贡献(MAR 非对称检索器 + 两阶段训练)
MAR:轻量查询编码器在线服务以降延迟,更强文档编码器离线建库保性能。
两阶段优化:(1)查询编码器对齐;(2)联合微调,直接面向检索目标。
结果:如
Figure1所示: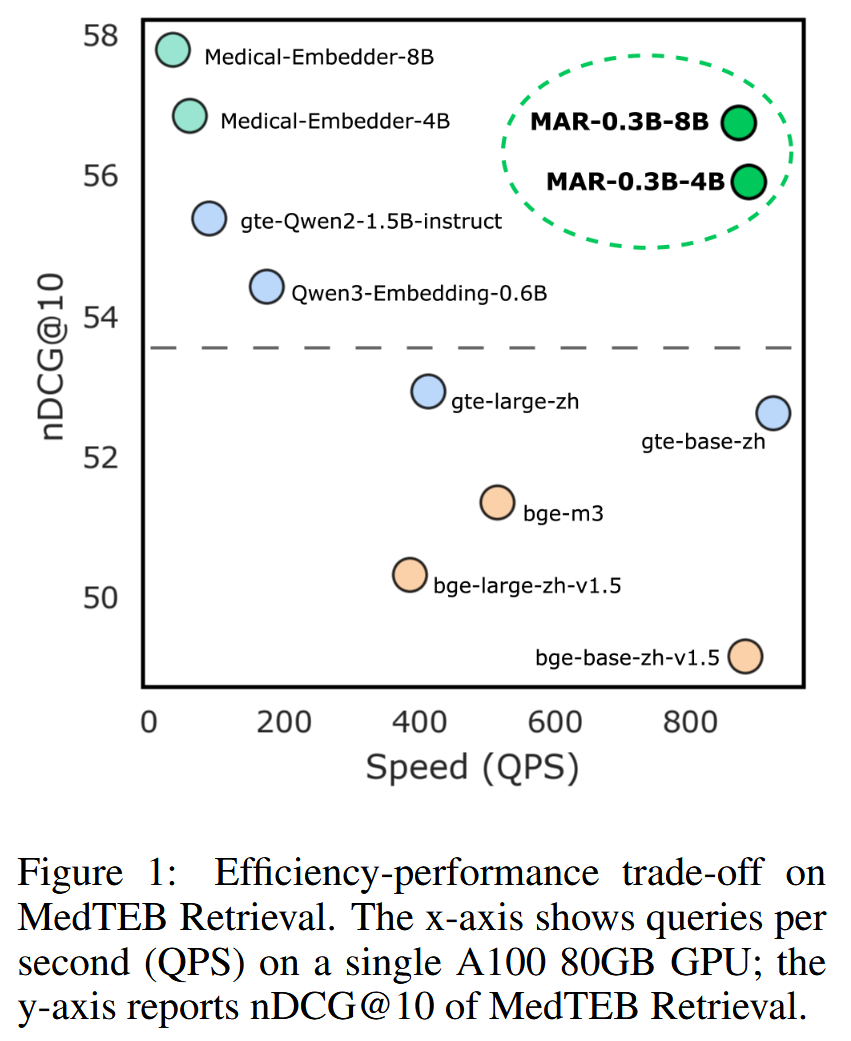
2 相关工作
Embedding Models
- 发展过程:从无监督对比预训练(如 Contriever)到大规模指令化/对比预训练(E5、GTE、BGE),通用语义表示显著提升。
- Decoder-only 兴起:Qwen3-Embedding、bge-en-icl、NV-Embed 等在 MTEB 上达 SOTA,证明仅解码器架构也能产出强嵌入。
- 瓶颈:多数 LLM-based 模型参数量大、延迟高、开销重,不适合实时医疗检索等延迟敏感场景:需要轻量且有效的领域嵌入。
Medical Embedding Benchmarks
MTEB 提供跨语种多任务评测;C-MTEB 纳入多项中文数据集。
已有医学相关数据(CmedqaRetrieval、MedicalRetrieval、CMedQA-v1/v2 等)虽被收录,但检索任务存在标注噪声与假负例,相对仅重排序更可靠。
缺少系统化、可信度高的中文医学嵌入基准 :MedTEB 即为弥补此缺口。
Asymmetric Architecture
两大路线:
(1) 裁剪+蒸馏:如 KALE,从大编码器裁剪层得到轻量查询塔,用 L2/KL 等对齐损失蒸馏教师知识;
(2) 异构编码器:如 ScalingNote、HotelMatch,查询/文档用不同架构或模态,通过对齐学习提升检索效果。本文不同做法:
(1) 文档塔用 decoder-only,天然适配异构对齐;
(2) 提出两阶段对齐框架(查询对齐+联合微调),直接面向检索优化;
(3) 不做高维投影:保持原始低维、检索更高效。
3 MEDTEB
中文医学嵌入基准稀缺;现有 CmedqaRetrieval、MedicalRetrieval 多源自问答配对,忽略跨样本的潜在相关答案,医学领域“主题强度”又放大了假阴性风险。
在问答配对式数据中,假阴性就是:本应相关的答案被标成负例,模型检索对了却被评测判错。医学场景尤甚——同一疾病/药物常有大量可通用的专业回答,配对之外的有效答案在标注里被遗漏而默认为负。例:查询“莫西沙星能和布洛芬一起吃吗?”标注只认 A 医生为正,把 B/C 医生在其他贴里给出的同样正确用药原则都记作负;模型检到 B/C 仍被判错。
实验依据:LLM 预标注显示——MedicalRetrieval 每条查询平均 8.6 个“被标负但可能相关”的候选;CmedqaRetrieval 约 19 个。
MedTEB:三项新任务(Retrieval / Reranking / Synonym STS)+ 两个人工核验公开数据(CMedQA-v1/-v2-reranking)。
3.1 CONSTRUCTION METHOD
- Retrieval:
- 多检索器召回 + 多 LLM 共识标注;数据为
(真实匿名查询)、 (标注后语料)、 。 - 与 AIR-Bench 做法的区别:(i) 医疗域、(ii) 真实查询、(iii) 多 LLM + 大候选池缓解误标负与未标注正。
- 多检索器召回 + 多 LLM 共识标注;数据为
- Rerank:
- 同样用多 LLM 标注,得正集
、负集 ;构造三元组 。
- 同样用多 LLM 标注,得正集
- STS:
- 先建医学同义词词表;对每个
,GPT-4o 生成: (同义保义)、 (同义改义)、 (非同义改义)。 - 采样
配对成 ,检验细粒度同义理解。
- 先建医学同义词词表;对每个
3.2 EVALUATION OF EXISTING EMBEDDING MODELS
数据规模(Table 1):
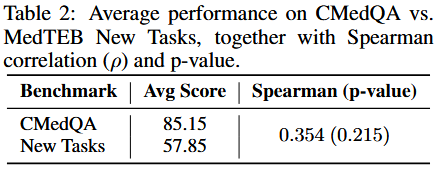
关键发现(Table 2):
- 通用嵌入在 CMedQA 与新任务:85.15 vs 57.85:新任务更具挑战、医学域欠发达。
- Spearman ρ=0.354, p=0.215(≫0.05):新任务非冗余,能从新视角评估模型。
- decoder-only 模型,如 Qwen3-Embedding-8B 在新任务平均 64.52;但延迟与算力成本高,限制真实应用。
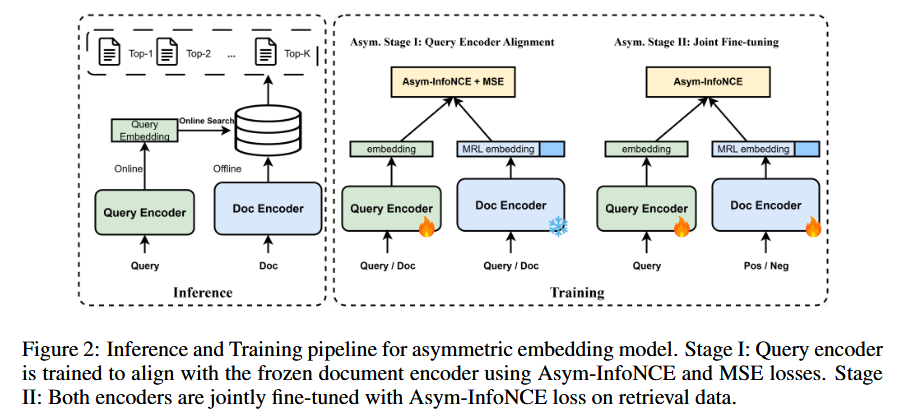
4 MEDICAL ASYMMETRIC RETRIEVER
鉴于现有模型在 MedTEB 上的局限性,作者提出非对称嵌入架构 + 两阶段训练:离线用更强的文档编码器(Doc Encoder)对全量语料向量化并建库;在线仅用轻量查询编码器(Query Encoder)编码用户查询进行近似向量检索。
4.1 HIGH-QUALITY DATA CONSTRUCTION
难点:医学“主题强度”导致潜在正样本多,传统 hard negative 工作流程常失效:
Top-k 挖负易夹带假阴性(未标注但相关的文档);
阈值过滤决策边界模糊;
对庞大候选池做全量 LLM 标注成本过高。
多样性感知三步管线:
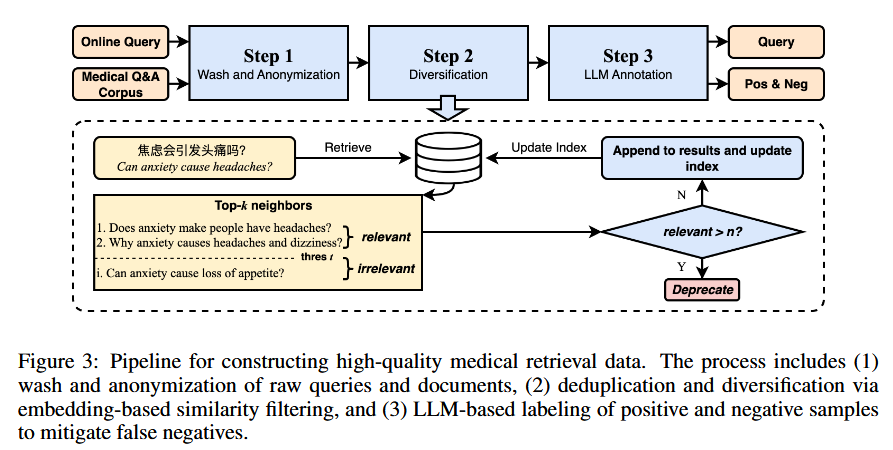
- 清洗与匿名化:从公开资源汇集中文医学语料
,并从线上服务收集真实匿名查询 ;去隐私、正则清洗、格式规范化。 - 去重与多样化:基于动态向量索引(先建索引、再以相似度阈值过滤)去语义近重复,并按主题做均衡采样,降低冗余、提升长尾覆盖。
- 候选内精标:对每个
由多检索器融合召回 Top-50 候选,再用 GPT-4o(多 LLM 共识)标注可靠正/负,最终产出约 50 万 检索三元组 。
- 清洗与匿名化:从公开资源汇集中文医学语料
自对齐数据(服务于非对称对齐):
查询侧:
共 2.8M; 文档侧:
共 5.6M;
其中正样由“文本与自身”构造,负样采用批内负为主。
4.2 INDEPENDENT INITIALIZATION
为给两塔注入领域知识并提供稳健起点,先训练一个对称双塔(Query = Doc 结构一致):
- 查询编码器(三级预训练 → 监督微调)
- RetroMAE 预训练:编码器/轻量解码器异步掩码;编码器产出句向量,解码器做 MLM 重构。语料:6000 万条中文医疗问答无监督语料。
- 无监督 InfoNCE 预训练:损失为 InfoNCE(温度 τ 可学习)。将标题–正文视作正对
,同 batch 其余样本作批内负。 - 有监督 InfoNCE 微调:在 §4 构建的高质量数据 + MedTEB 训练划分(Retrieval、Rerank、CMedQA v1/v2、Synonym STS)上,用 InfoNCE 端到端优化检索表征。
- 文档编码器(大模型微调 + 多维嵌入)
- LoRA 微调:以 Qwen3-4B / Qwen3-8B 为底座,rank=32,α=64,在控制算力的同时保持性能。
- MRL(Matryoshka Representation Learning):训练嵌套维度集合
,在每个目标维度上各自计算 InfoNCE,并对所有维度的损失求平均。推理时可截断到前 m 维以匹配轻量查询塔的向量维度,兼顾精度/延迟/索引大小的部署弹性。
初始化后得到一个 性能稳健的对称表示空间,为后续的 非对称对齐(Stage I) 与 联合微调(Stage II) 打下基础。
4.3 ASYMMETRIC EMBEDDING ARCHITECTURE
- 范式:
离线:Doc Encoder 对全集语料向量化,构建向量索引(可用余弦/内积);
在线:Query Encoder 编码用户查询,进行 ANN 检索(HNSW/FAISS 等实现可替换)。
- 难点:轻量查询塔与强力文档塔嵌入空间天然不对齐。
4.3.1 ASYMMETRIC STAGE I: QUERY ENCODER ALIGNMENT
做法:冻结 Doc Encoder(教师),仅更新 Query Encoder(学生)。训练数据采用上节的自对齐集合与检索候选池中的正/负。
目标函数(混合对齐):
- Asym-InfoNCE(相对排序对齐)
其中
, , 为余弦相似(向量已归一化), 为温度, 为负样数量(批内负为主)。在自对齐样本上, 与 为同一文本,可稳定拉近两塔同源表示。 - MSE(绝对位置对齐)
直接惩罚同一文本在两塔中的向量距离,补充“坐标级”的对齐约束。
- 联合损失
- Asym-InfoNCE(相对排序对齐)
直觉:Asym-InfoNCE 提供相对排序信号,MSE 提供绝对位置信号;两者协同可更稳地缩小两塔语义鸿沟,避免仅有排序信号时的漂移。
4.4 ASYMMETRIC STAGE II: JOINT FINE-TUNING
- 目标:在初步对齐的基础上,端到端提升检索判别力。
- 做法:解冻两塔,仅以 Asym-InfoNCE 为训练目标;结合批内负 + 硬负丰富难例。
- 结果:最终得到 MAR(Medical Asymmetric Retriever)系列模型——在 MedTEB 上取得强精度,同时在线仅跑轻量查询塔、离线预计算文档塔,实现SOTA 级准确率 × 小模型级 QPS/延迟的现实可用折中。
5 实验
5.1 SETUP
- Models
- Query:Medical-Embedder-base(由 gte-multilingual-mlm-base 初始化,≈0.3B 参数)。
- Document:Medical-Embedder-4B / -8B(在 Qwen3-4B / Qwen3-8B 上微调)。
- Asymmetric 变体:MAR-0.3B-4B(0.3B Query + 4B Doc)、MAR-0.3B-8B(0.3B Query + 8B Doc)。
- Baselines:BGE、GTE、Qwen3-Embedding、Conan-embedding-v1、stella-base-zh-v3-1792d 等。
- Training Data(统一)
第4节的高质量微调集 + MedTEB 训练划分(Retrieval / Rerank / CMedQA / Synonym STS)。即便部分baseline在预训练阶段见过 CMedQA,仍显式纳入以避免该任务潜在性能下降。 - Implementation
- 检索评估:用 FAISS 近邻检索。
- 总exposure量对齐:所有对称基线 fine-tune 2 个 epoch,与本文提出的MAR总exposure量匹配。
- 计算资源:32× A100-40GB。
5.2 MAIN RESULTS ON MEDTEB
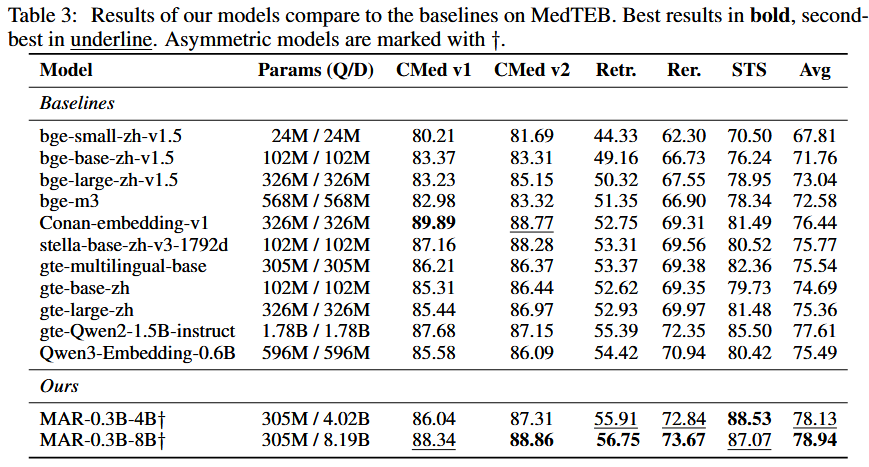
- SOTA:
- MAR-0.3B-4B 平均 78.13,MAR-0.3B-8B 平均 78.94;均超过最强基线 gte-Qwen2-1.5B-instruct = 77.61(decoder-only),且Query 仅 0.3B。
- 扩展性:
- 将文档塔 4B → 8B,平均提升 +0.81;查询时延不变(Query 仍 0.3B)。
5.3 ASYMMETRIC vs. SYMMETRIC
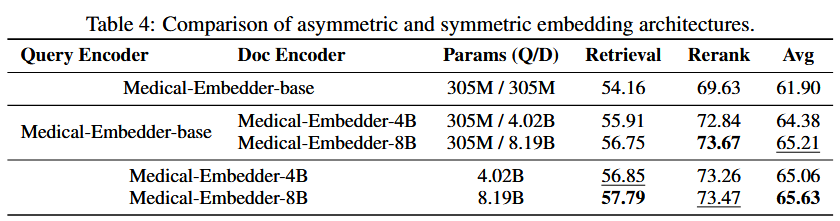
非对称方案逼近大文档模型的上限(8B 对称 65.63 vs. 8B 非对称 65.21),同时远超轻量对称;放大 Doc 塔能单向提升精度,且不增加查询时延。
5.4 ABLATION STUDY
5.4.1 Training Design
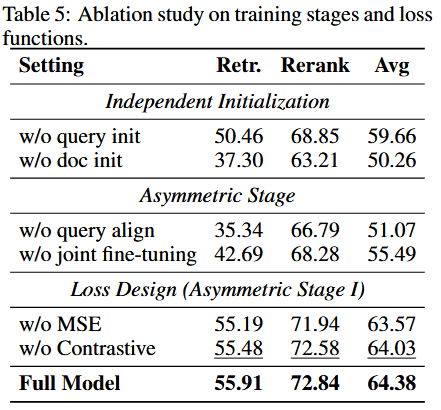
- 独立初始化缺一不可:去掉 Query init → 59.66;去掉 Doc init → 50.26;完整模型 64.38。
先训对称双塔为非对称阶段提供更强起点至关重要。
- 两阶段都重要:无 Query 对齐 → 51.07;无联合微调 → 55.49;完整 64.38。
对齐阶段让学生 Query 学到教师 Doc 的空间,联合微调让两塔适配下游检索。
- 损失设计(Stage I):去 MSE → 63.57;去对比项 → 64.03;两者并用 64.38(最佳)。
**相对排序(Asym-InfoNCE)+ 绝对位置(MSE)**均有贡献。
5.4.2 Query Alignment Data
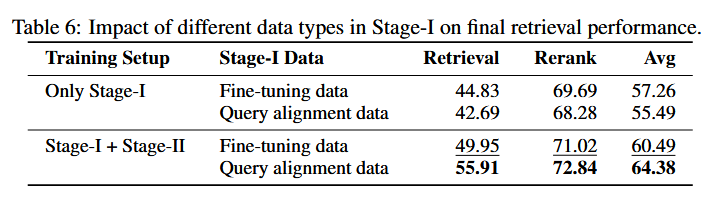
- 仅做 Stage-I:用“fine-tuning 数据”57.26 > “alignment 数据”55.49。
- 再接 Stage-II:先用 alignment 数据的最终表现 64.38 > 先用 fine-tuning 数据 60.49。
对齐专用数据更能铺好表示空间、抬高性能上限;直接用下游数据做对齐易过早收敛、表达不佳。
5.4.3 Alternatives to Efficient Retrieval
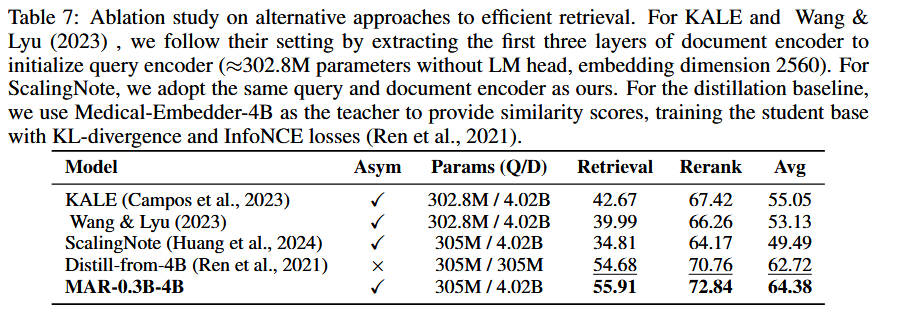
- KALE:55.05;Wang & Lyu (2023):53.13;ScalingNote:49.49(均为非对称)。
- Distill-from-4B(对称蒸馏学生):62.72。
- MAR-0.3B-4B:64.38(最佳)。
编码器裁剪/分数蒸馏在decoder-only场景下适配有限;直接把强 Doc 作为教师并保留其离线向量,可避免蒸馏信息损失,检索效果更强。
6 结论
本文发布中文医学嵌入新基准 MedTEB,并提出面向低延迟医疗检索的非对称模型 MAR(轻量查询侧 + 大规模文档侧,二阶段对齐/微调)。在 MedTEB 上取得 SOTA,并开源基准、模型与训练流程,为真实医疗 RAG 落地与领域嵌入研究提供实践方案与起点。
我的思考
读完这篇论文,我学习到了一条可落地的路线:把“强能力”放在离线的文档塔,把“低时延”放在在线的查询塔。这种非对称设计天然适配需要实时响应的检索/RAG;迁移到多模态时,也只需把文档塔换成强 VLM/MLLM,查询侧保留轻量编码头即可。
同时,本文的训练策略也很关键:先做一次对称初始化给两塔注入领域知识;随后 Stage-I 冻结文档塔,只训查询塔,用 **Asym-InfoNCE(相对排序)+ MSE(绝对位置)**把两塔空间拉齐;最后 Stage-II 解冻两塔,仅用 Asym-InfoNCE 面向检索目标端到端优化。这里的一个小技巧值得照搬——对齐专用数据:
数据层面,我明白高质量数据的价值,通过在 Top-K 候选里精做数据——多检索器召回→多 LLM 一致性复核→必要时允许多正样 的做法,专门对付医学场景里“主题强度高导致假阴性多”的难点。做多模态时,同样可以考虑把一致性扩展成 VLM+LLM 双通道。
最后是如何从实验结果中分析:一方面,针对精度&效率双线(nDCG@10/Recall@k + QPS/显存/延迟),探究“文档塔变大、查询时延不变”的收益;另一方面,通过轻量诊断——假阴性(每查询的可疑负例数+抽检通过率)、错误切片(实体/同义/否定等维度),以及对齐前后余弦相似度确认空间收敛。
MAR: MEDICAL ASYMMETRIC RETRIEVER FOR EFFICIENT CHINESE MEDICAL DENSE RETRIEVAL 阅读笔记