
Asymmetric Feature Fusion for Image Retrieval阅读笔记
金培晟 Jarfield
0 Abstract
在非对称检索系统中,不同容量的模型部署在不同计算与存储资源的平台上。尽管已有方法取得进展,受限于查询端轻量模型的能力,现有方法在检索效率与非对称准确率之间仍存在两难。本文提出一种 Asymmetric Feature Fusion(AFF)范式:仅在图库(gallery)侧考虑不同特征之间的互补性。具体做法为:首先将每个图库图像嵌入为多种特征(例如局部特征与全局特征);随后引入动态 mixer 聚合这些特征为用于高效检索的紧凑嵌入。查询侧仅部署单个轻量模型进行特征提取。查询模型与动态 mixer 通过共享的动量更新分类器联合训练。该范式在不增加查询侧任何开销的前提下提升非对称检索准确率;在多个 landmarks 检索数据集上的详尽实验验证了其优越性。
1 Introduction
图像检索长期以来被广泛研究。传统高性能系统常在查询与图库两侧部署同一大模型(对称检索),但在如移动搜索等资源受限场景,查询端无法承载大模型开销,社区遂发展出非对称检索(Figure1(a)):图库侧用强模型,查询侧用轻模型,并通过兼容性训练对齐两侧嵌入空间。
.png)
然而,受轻量模型容量所限,现有非对称方案相较对称检索仍有明显准确率损失,尤其在大规模与受限资源场景中。本文从“特征融合”视角提出 AFF(Figure1(b)):在图库侧部署多种强特征提取器(涵盖全局与局部),再以动态 mixer 聚合为单一紧凑向量以支持高效向量检索;查询侧仅用单一轻量模型,并与 mixer 通过动量更新分类器进行联合训练,实现不增加查询端开销的同时显著提升非对称检索精度。
.png)
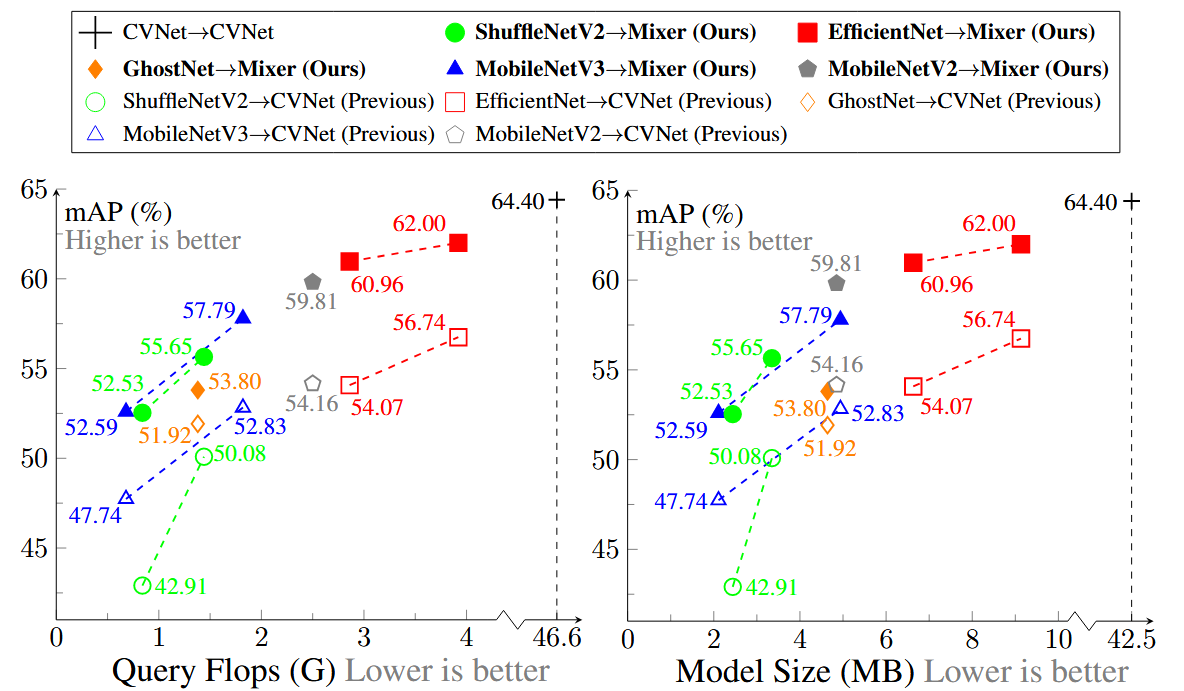
查询端 FLOPs/模型大小 与 平均 mAP 的关系:在相似或更低查询端开销下,AFF 曲线整体更优。(Figure2)
2 Related Work
非对称检索研究可从特征表示与兼容、轻量网络、特征融合三线把握:从手工局部特征过渡到 CNN 表示后,全局特征以空间池化将激活汇聚为单向量,局部特征保留关键点/patch 描述子以供几何一致性重排;VLAD/ASMK 等聚合方法将海量局部描述子压缩为可检索表示。为提升跨模型功能兼容,实践结合蒸馏、共享原型、相似度分布对齐与线性映射等策略,使轻量与重型模型在同一度量空间内可比;查询端采用 MobileNet/ShuffleNet/GhostNet/EfficientNet 等以满足 FLOPs/延迟约束。传统多特征融合多要求查询端多路提特征从而拉高时延与内存,而 AFF 将多源特征仅置于图库侧离线提取并做中期动态融合,输出单向量即可完成高效检索,在不增加查询端开销的前提下带来稳定精度收益。
Tips
- CNN 全局/局部与聚合:MAC 取通道空间最大值;SPoC 做全局平均;R-MAC 多尺度区域 max-pool 后加权汇聚;GeM 用可学习幂次在 avg/max 间自适应;VLAD 将局部指派至 codebook 并累积残差成定长向量;ASMK 对匹配词条做选择性聚合与归一化以抑制噪声。
- 跨模型兼容性:embedding distillation 最小化强/弱特征差;共享原型/分类器用统一 proxy 约束边界;compatibility loss 对齐跨模型相似度/角度分布;线性映射将轻量特征投影到重型空间;动量原型减耦合与震荡;温度/边距校准统一置信度与间隔。
- 融合层次:早期(特征级)先对齐维度再拼接/投影;中期(表示级)用注意力/Transformer 对 token/region 动态加权(AFF 属此类且在图库侧执行);后期(决策级)在相似度或排序分数上集成多路结果。
3 Preliminary on Asymmetric Retrieval
非对称检索在查询侧与图库侧分别部署不同容量的模型
4 Asymmetric Feature Fusion
4.1 Overview
图库侧同时部署
随后映射到同一维度
引入 mixer
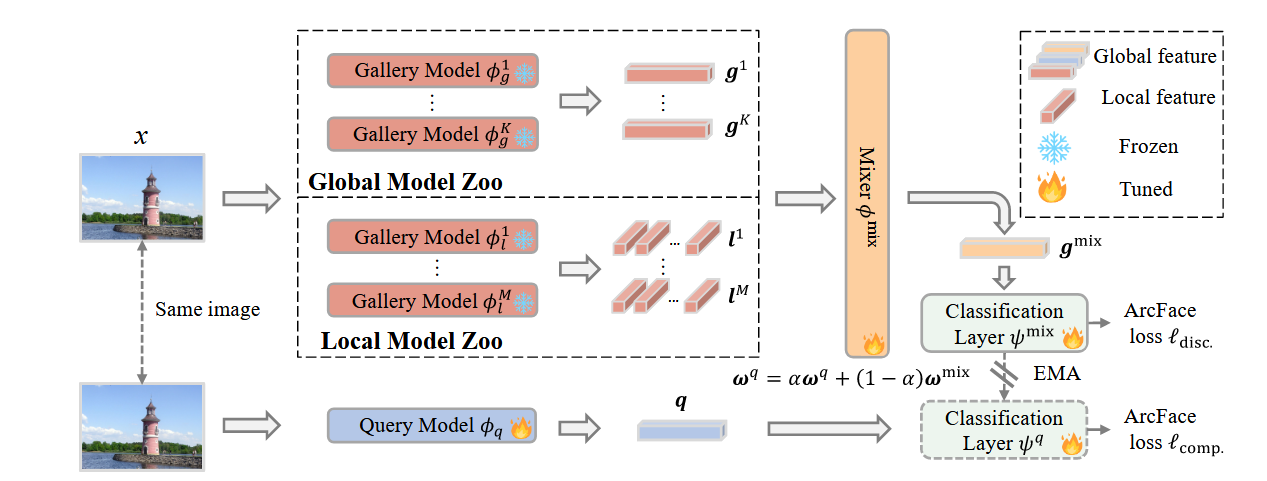
框架总览:图库侧多模型提特征 + 动态 mixer;查询侧轻量模型;两侧经 ArcFace 分类器(查询侧为动量更新版本)联合优化。(Figure3)
4.2 Dynamic Mixer
为避免简单拼接 + 降维带来的过参数与过拟合,本文以 Transformer 层实现“动态特征聚合”。先在特征序列顶端加入可学习融合 token
对
其中
Tips:
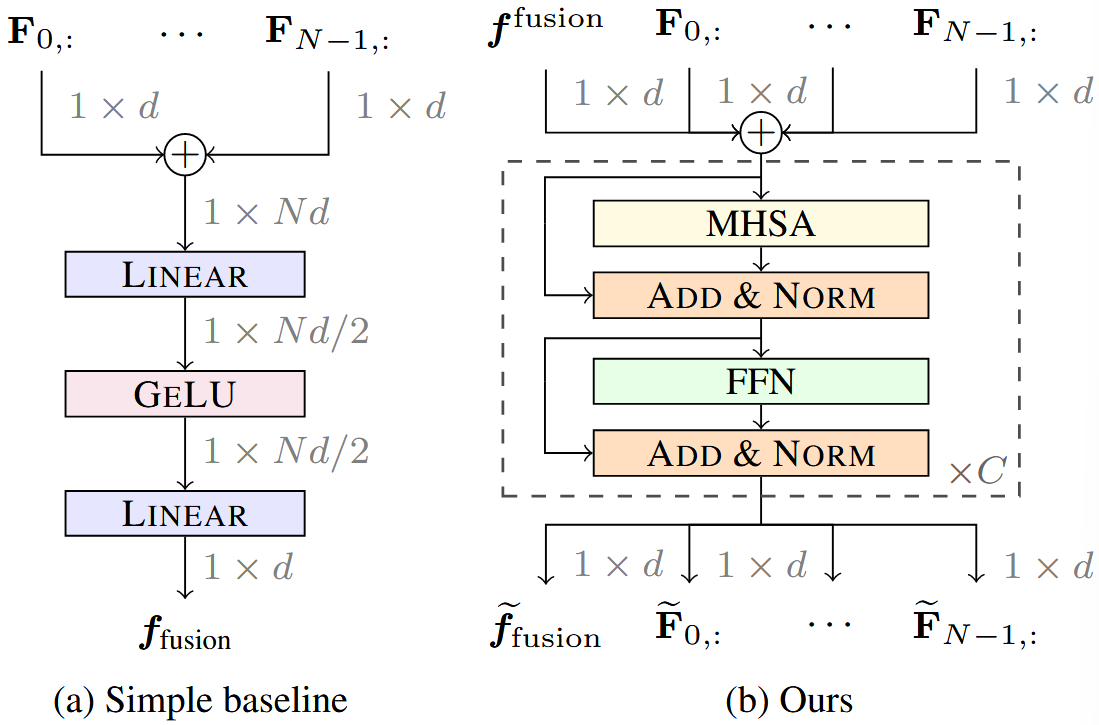
- 过参数与过拟合:参数量相对样本与信号复杂度过大易记忆训练噪声,导致训练误差低而泛化误差高;使用共享参数与注意力聚合替代“拼接+大降维”可降低冗余并提升稳健性。
- Transformer 层缩写:LN(LayerNorm,层归一化,稳定数值与梯度);MHSA(Multi-Head Self-Attention,多头自注意,建模异质特征间依赖);MLP(前馈网络,非线性变换与融合);GELU(高斯误差线性单元,平滑激活)。
mixer 变体:简单拼接 vs. 采用融合 token 的 Transformer 聚合。 (Figure4)
4.3 Training Objective Functions
目标是同时保证聚合图库向量
判别性(gallery 侧)
其中
兼容性(query 侧)
其中,
Tips:
聚合图库向量; 查询向量; 类别原型; 真实类别; 缩放; 边距; 与对应原型的夹角; 动量系数。
5 Experiments
5.1 Experimental Setup
- Datasets → metrics:GLDv2-Test(gallery 761,757;public/private queries 390/750;mAP@100)→ 小规模 ROxf/RPar(各 70 queries;gallery 4,993/5,007;报告 Medium/Hard)→ 加入 R1M 得到 +1M 大规模评测。
- Gallery features → 组合:全局(DELG、Token、DOLG、CVNet)+局部(HOW、DELG),全部离线抽取;Query 仅保留轻量 backbone(ShuffleNet/MobileNet)+ GeM + whitening。
- 训练集 → 规模:GLDv2(1,580,470 images,81,311 类),gallery 侧特征离线以提速。
5.2 Ablation Study
- Mixer 架构 ↗:带融合 token 的 Transformer 优于 MLP/LAFF/OrthF 等(ROxf+1M Medium/Hard:77.84/58.91;RPar+1M:84.43/69.44)。
- 特征逐步融合同步 ↗:从少到多引入全局/局部特征,mAP 单调提升,最终达到上面的最佳值。
- 鲁棒性 → 噪声:基于融合 token 的动态聚合对“无益/噪声”特征更稳健。
5.3 Applicability & Training Strategy
(A)可用性/延迟对比
- 重排 vs 单向量检索:在“全局检索→局部重排”流水线下,GV/RRT 检索时延(RET) 显著增加:
- GV:12.752 s → 0.345 s(用 AFF,RET↓97.3%);RRT:1.875 s → 0.345 s(RET↓81.6%)。同时在非对称设置下 Query 侧抽取时延(EXT) 由 425.4 ms → 16.5 ms。
- 精度 ↑ + 开销 ↓:在相同场景下,AFF(仅向量检索)在 mAP 上高于重排法,且无需在线局部特征,显著降低查询端负担与在线时延。
(B)动量 α 与训练方式
- α 扫描(0 → 0.999)↗:GLDv2-Private 25.86 → 29.85(↑3.99),ROxf+1M-Medium 62.75 → 70.47(↑7.72),RPar+1M-Hard 50.63 → 62.58(↑11.95);最佳区间 α∈[0.99, 0.999]。
- 端到端(Joint)优于两阶段(Two-stage):以 Ours 为例,GLDv2-Private 27.90 → 29.85,ROxf+1M-Medium 66.76 → 70.47(全数据集一致提升)。
- 解耦训练(动量)提升泛化:将 AFF 与 REG/LCE/CSD 结合时,解耦显著胜过耦合;如“Mixer + CSD”在 ROxf+1M-Medium 48.31 → 69.66(↑21.35),Hard 29.49 → 46.82(↑17.33)。
5.4 Larger Gallery Models vs. Fusion
- 仅放大单一 gallery 模型 ≠ 一定更好:Swin-L(197 MB)相较 Swin-B(88 MB)并未稳定提升;而Mixer 融合(DELG+Token+DOLG+CVNet)在对称/非对称均取得更高 mAP。
- 例:对称(Mixer/Mixer)GLDv2-Private 32.93、ROxf+1M-Medium 77.58;非对称(MobV2/Mixer)ROxf+1M-Medium 68.17。
- 训练成本 → 更优性价比:放大模型带来显著训练开销;AFF 仅需训练轻量融合网络并冻结各特征提取器。
关键发现
- 仅图库侧融合,多源互补 + 单向量检索在精度-时延-内存三维上优于“查询端多路/重排”。
- 动量解耦既提升数值也提升训练稳定性/可泛化性;联合训练进一步放大收益。
6 Conclusion
本文提出的 AFF 在图库侧融合多路全局/局部特征,并用动态 mixer 聚合为单向量,结合查询侧轻量模型与动量更新分类器的联合训练,实现了在不增加查询端开销的前提下显著提升非对称检索准确率;多数据集实验显示该范式具有良好通用性与有效性。
个人思考
- 我从这篇论文学到:
- 以图库侧多特征融合替代查询侧多路提特征,是在“离线重+在线轻”制约下的系统级优化思路;Transformer 式融合 token能在异质特征间做动态注意力分配。
- 动量解耦的共享分类器既避免了直接共享导致的训练耦合与不稳定,又维持了跨模型原型的一致参照。
- 设计上用 ArcFace 作为判别性/兼容性的统一训练目标,工程上易于落地,配合简单 SGD/超参即可复现。
- 可以借鉴到我的工作:
- 在“离线重编码 + 在线轻检索”的多模态检索中,将视觉/文本/跨模态的若干强表征离线融合为单向量,在线仅做一跳向量搜索;查询端仍维持轻量 encoder。
- 采用动量原型对齐轻量查询模型与库侧融合表征;做一组
扫描实验(0.9→0.999)并报告 mAP–延迟权衡曲线。
- 可能的改进或开放问题:
- 特征选择与噪声鲁棒:实际工程中引入的某些特征可能对特定数据分布无益,考虑在 mixer 中加入稀疏门控/路由或不确定性估计以抑制噪声特征。
- 跨模态扩展:将图库侧的局部/全局视觉特征与文本、OCR 或布局特征一并融合,探索跨模态融合 token的适配性。
- 可部署性:进一步压缩 mixer(蒸馏/量化/结构化剪枝),并研究与 ANN 索引(如 HNSW/IVF-PQ)的协同设计,保持单向量高效检索。
Asymmetric Feature Fusion for Image Retrieval阅读笔记